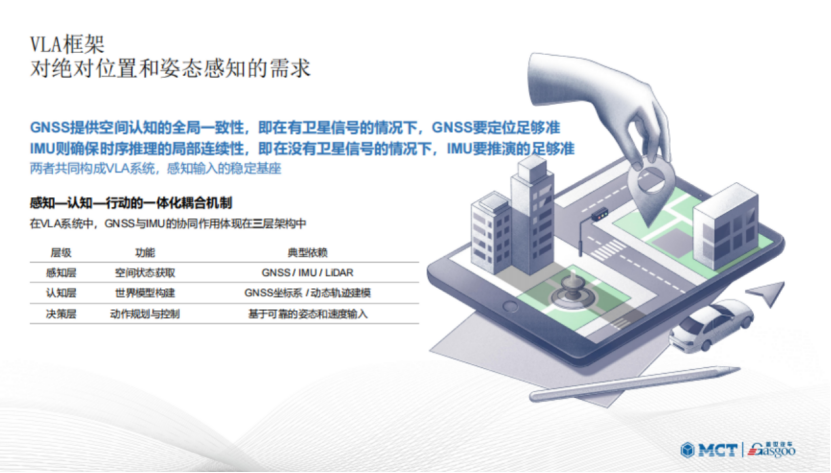
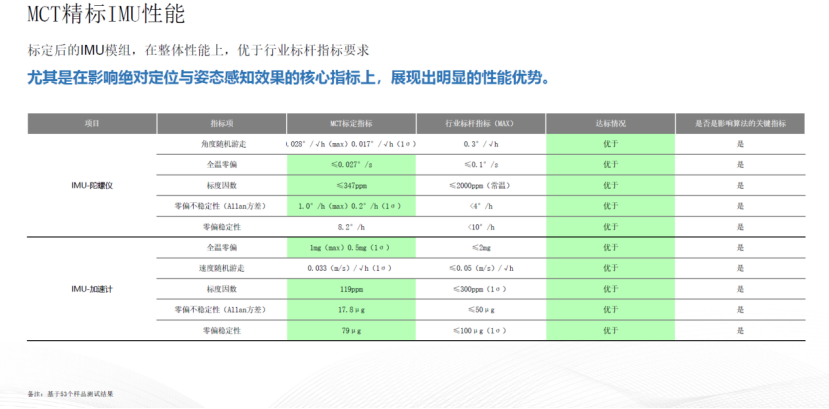
In the context of the evolving smart driving architecture, the reliability of perception systems has transformed from a concern regarding auxiliary module indicators to a fundamental challenge of whether the entire system can operate stably in a closed loop. This is particularly true in high-complexity urban scenarios where frequent GNSS occlusions, dynamic road conditions, and increasingly complex semantic reasoning challenge perception systems to not only 'see' but also 'see steadily, accurately, and continuously.' At the '2025 Eighth Intelligent Auxiliary Driving Conference - Perception Fusion Session,' Hu Yang, the Business Director of MCT, delivered a keynote speech titled 'Soft-Hard Integration, AI Empowerment: Supporting Reliable Absolute Positioning and Attitude Perception in the VLA Era.' He emphasized that as the Vision-Language-Action (VLA) architecture becomes a significant direction for the development of next-generation intelligent driving technology, attitude perception and absolute positioning are no longer peripheral aspects of the perception chain but rather the foundational supports for AI systems in spatial understanding, path decision-making, and action execution. To achieve continuous and stable spatial state input in complex urban environments, deep collaboration between GNSS and IMU is essential, supported by an integrated hardware-software design that connects chips, modules, and fusion algorithms to build a combination navigation system capable of mass production. During the presentation, MCT showcased three major technology platforms and a full-stack solution centered around 'reliable perception,' proposing a methodology of 'soft-hard integration, data-driven' approach to provide the industry with insights into building spatial perception capabilities for future AI architectures. The evolution of intelligent auxiliary driving architecture has experienced several stages: First, the two-stage architecture from the early to mid-2010s, characterized by modular design that separates perception, planning, and decision-making into two stages. A typical example is Tesla's Autopilot 1.0. Next came the one-stage architecture in the mid to late 2010s, integrating perception and decision-making through neural networks, although planning still relied on rule engines, exemplified by Tesla's HW 3.0. Following that was the VLM (Vision-Language Model) architecture in the early 2020s, which introduced natural language understanding, combining visual and semantic information, with Huawei's Pangu model being a typical example. Then we arrived at the E2E (End-to-End) architecture that has been prevalent since 2020, employing full-stack neural networks that require no manual rule design from sensor input to final output, exemplified by Tesla's FSD V12. Currently, we are in the VLA (Vision-Language-Action) architecture era, a product of the synergy between large model technology, multi-modal demands, and computational infrastructure, likely becoming a core component of the next generation of general artificial intelligence. The architecture's evolution inevitably triggers a series of changes, requiring higher computing power, more cameras, and denser Lidar setups from an incremental perspective. Additionally, it has led to shifts in demand and technology integration. For instance, GNSS has evolved from supporting dual-frequency GNSS with on-chip RTK algorithms to a need for vehicle-grade output of raw observations across three frequencies. Similarly, IMUs have transitioned from standalone IMU boxes to being integrated into high-precision IMU modules on boards. Furthermore, customer applications are increasingly merging; GNSS must not only serve domain control but also provide cabin services, while IMUs need to support both domain control and chassis, airbag controller services. Industry focus has also shifted; initially, attention was on positioning accuracy under CEP 68 and CEP 95 conditions, whereas now clients expect comprehensive positioning capabilities across all scenarios. Amidst these changes, reliability remains the constant. The more advanced the technical architecture, the higher the reliability demands for combination navigation algorithms and hardware. In summary, the demand for absolute positioning and attitude perception within the VLA architecture can be encapsulated in one phrase: precise positioning is a prerequisite for the VLA model to execute language understanding and action execution. The discussion will unfold across five aspects: Firstly, the importance of positioning accuracy, which provides the VLA model with reliable spatial information, forming the foundation for environmental semantic understanding and intelligent decision-making, directly impacting driving safety and stability. In simple terms, 'the positioning must be accurate.' Secondly, regarding the data sources for absolute positioning and attitude perception, the VLA architecture relies on multi-source fusion technologies like GNSS and IMU to ensure precise positioning capabilities even in complex scenarios, which can be summarized as 'typical dependency.' Thirdly, real-time requirements for positioning. The VLA model requires real-time updates of vehicle position information during driving tasks to ensure efficient collaboration between perception, planning, and control modules, thereby enhancing response speeds in intelligent auxiliary driving, summarized as 'real-time location.' Next is the relationship between multi-modal data synchronization and accurate positioning; accurate positioning must synchronize and fuse with visual and language modality data to enhance the system's understanding of its surrounding environment, enabling more accurate semantic understanding and action execution, summarized as 'data synchronization.' The fifth point is the impact of positioning errors, which can lead to misjudgments of environmental information by the VLA model, affecting path planning and behavior decision-making. Therefore, it is essential to implement correction mechanisms to improve the overall system reliability, summarized as 'must be reliable.' Furthermore, GNSS provides global consistency for spatial cognition; when satellite signals are available, GNSS positioning should be sufficiently accurate, while the IMU ensures local continuity of temporal reasoning, maintaining accuracy even in the absence of satellite signals. Together, they form the stable foundation for perception input in the VLA system. Within the VLA framework, the collaboration between GNSS and IMU manifests in a three-layer architecture: the first layer is the perception layer, responsible for acquiring spatial states, relying on GNSS, IMU, and Lidar; the second layer is the cognitive layer, which builds the world model, typically relying on dynamic trajectory modeling in the GNSS coordinate system; the third layer is the decision layer, responsible for action planning and control, relying on reliable attitude and speed inputs. Based on these requirements, MCT offers a full-stack solution.
MCT Presents Advances in Reliable Positioning and Attitude Perception for VLA Era

Images








Share this post on: